Redis 的持久化功能保证了即使在服务器重启的情况下也不会损失(或少量损失)数据。但是单机出现故障还是会出现数据丢失。Redis 提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
Redis 的主从架构中,可以是一主一从,也可以是一主多从,也就是一个master可以有多个slave,也就相当于有了多份的数据副本。在redis主从架构中,Master节点负责处理写请求,Slave节点只处理读请求,除了主从同步,redis也可以从从同步。
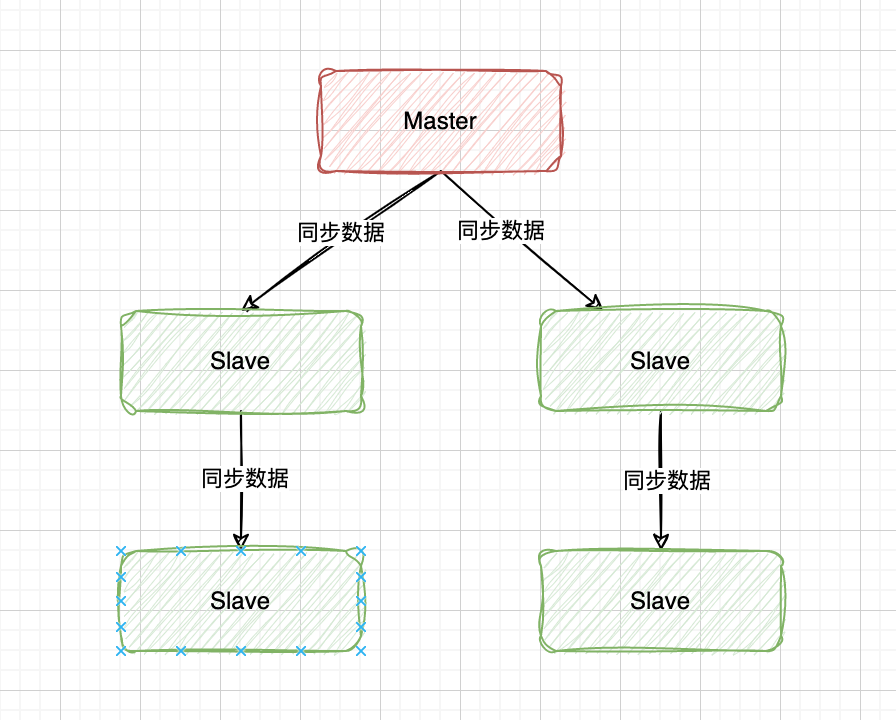
同步的原理和步骤
主从同步主要是通过 RDB 文件和主库维护的一个积压队列来实现的。
第一次同步的时候,或者是直接输入命令的时候都会进行同步。
当客户端向服务器发送SLAVEO命令(新版的是replicaof),要求从服务器复制主服务器时,从服务器首先需要执行同步操作。
从服务器对主服务器的同步操作主要是通过SYNC命令来完成,下面是步骤
- 从服务器向主服务器发送sync命令
- 主服务器收到sync命令之后,执行bgsave命令,在后台生成一个RDB文件,并使用一个缓冲区记录从现在开始执行的所有写命令
- 主服务器执行完毕bgsave之后,把生成的rdb文件发送给从服务器,从服务器载入rdb文件同步数据
- 主服务器将记录在缓存区中的所有写命令发送给从服务器,从服务器执行这些写命令,更新到现在主库的状态
全量同步
在2.8版本之前,Redis 只支持全量同步。
初次同步的时候,首先需要在主节点上进行一次 bgsave 将当前内存的数据全部快照到RDB文件中,然后再将快照文件的内容全部传送到从节点。从节点将RDB文件接受完毕后,立即执行一次全量加载,加载之前先要将当前内存的数据清空。加载完毕后通知主节点继续进行增量同步。
Master 和 Slave 网络发生了抖动,那一段时间内这些数据就会丢失,对于 Slave 来说这段时间 Master 更新的数据是不知道的。最简单的方式就是再做一次全量复制,从而获取到最新的数据,在redis2.8之前是这么做的。
全量复制的开销
1.bgsave的开销,每次bgsave需要fork子进程,对内存和CPU的开销很大
2.RDB文件网络传输的时间(网络带宽)
3.从节点清空数据的时间
4.从节点加载RDB的时间
5.可能的AOF重写时间(如果我们的从节点开启了AOF,则加载完RDB后会对AOF进行一个重写,保证AOF是最新的)
增量同步
Master 节点会将写命令记录在本地的内存 buffer(复制缓冲区) 中,然后异步发送给 Slave 节点,Slave 节点一边执行同步的指令流来达到和主节点一样的状态,一边向主节点反馈自己偏移量。内存的 buffer 是有限的,只能记录一部分内容,如果 buffer 内容满了,就会从头开始覆盖前面的内容。
主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果偏移量之后的数据仍然存在于复制积压缓存区里面,主服务器将对从服务器执行部分同步操作,如果网络中断时间过长,造成主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制