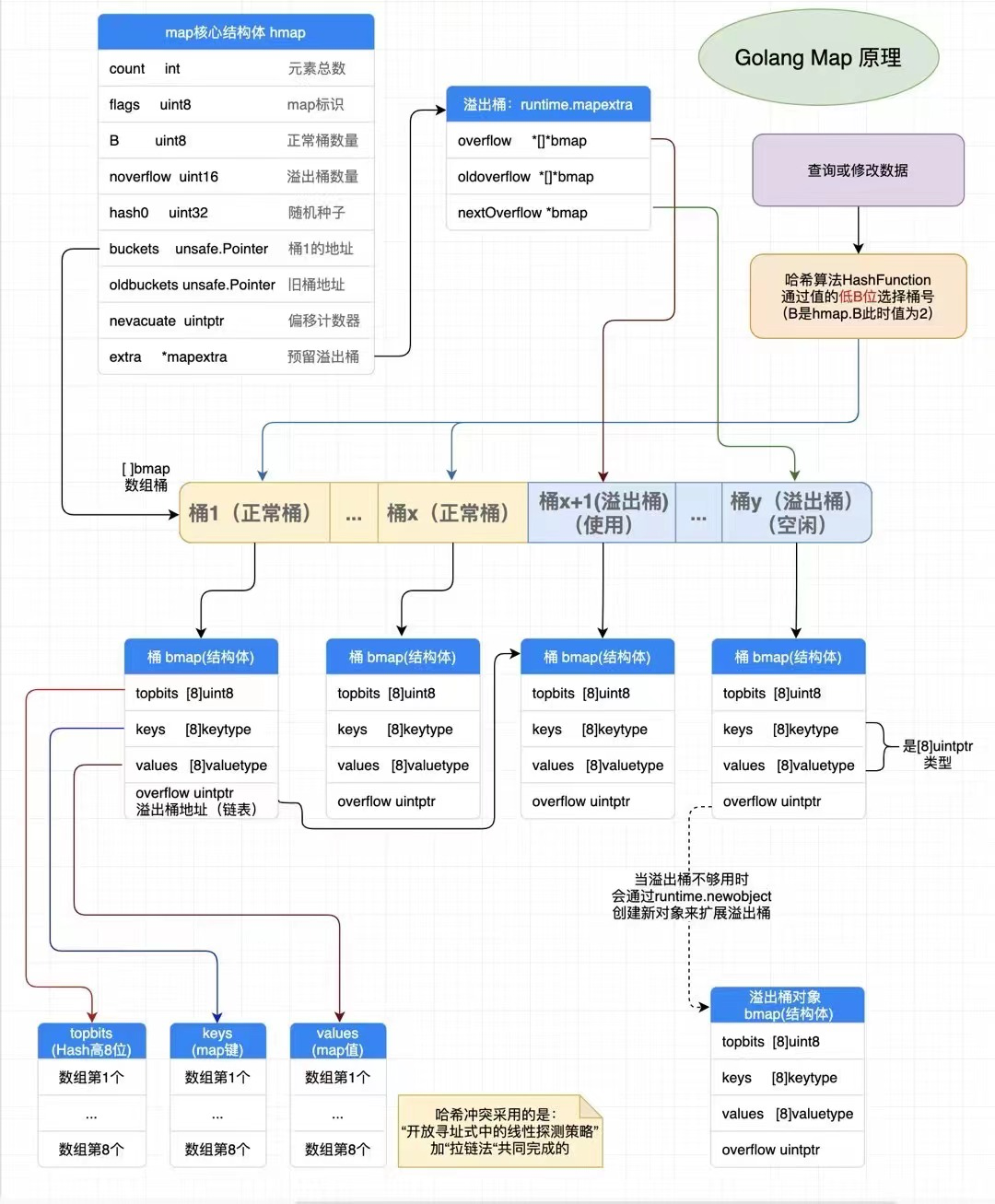
funcmakemap(t *maptype, hint int, h *hmap) *hmap { mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size) if overflow || mem > maxAlloc { hint = 0 }
// initialize Hmap if h == nil { h = new(hmap) } h.hash0 = fastrand()
// 按照提供的元素个数,计算所需要的桶的数量 B := uint8(0) for overLoadFactor(hint, B) { B++ } h.B = B
// allocate initial hash table // if B == 0, the buckets field is allocated lazily later (in mapassign) // If hint is large zeroing this memory could take a while. if h.B != 0 { var nextOverflow *bmap h.buckets, nextOverflow = makeBucketArray(t, h.B, nil) if nextOverflow != nil { h.extra = new(mapextra) h.extra.nextOverflow = nextOverflow } }
return h }
函数的执行逻辑
计算哈希占用的内存是否溢出或者超出能分配的最大值
调用runtime.fastrand获取一个随机的哈希种子;
根据传入的hint计算出需要的最小需要的桶的数量;
使用runtime.makeBucketArray创建用于保存桶的数组;
runtime.makeBucketArray会根据传入的 B 计算出的需要创建的桶数量并在内存中分配一片连续的空间用于存储数据:
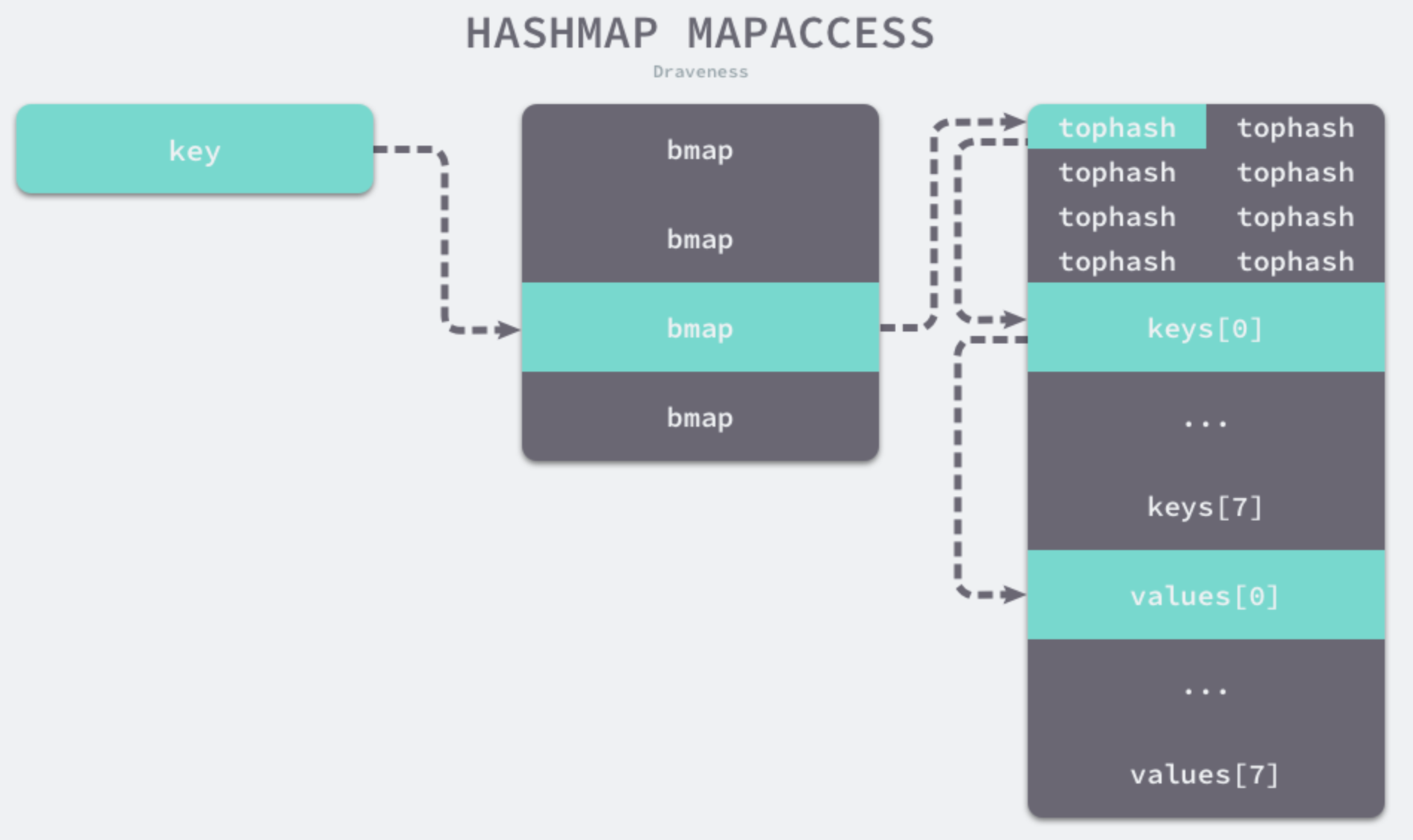
funcmapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { // --省略代码-- // 计算hash值 hash := t.hasher(key, uintptr(h.hash0)) m := bucketMask(h.B) // b 就是 bucket 的地址 b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize))) // oldbuckets 不为 nil,说明发生了扩容 if c := h.oldbuckets; c != nil { // 判断是不是同容量扩容,如果不是,那就是2倍扩容 | same:相同 if !h.sameSizeGrow() { // There used to be half as many buckets; mask down one more power of two. m >>= 1 } oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize))) if !evacuated(oldb) { b = oldb } } // tophash 取其高 8bit 的值 top := tophash(hash) bucketloop: // 依次遍历正常桶和溢出桶中的数据 for ; b != nil; b = b.overflow(t) { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { // emptyRest意思后面都是空的了 | [h1][h2][h3][h4][h5][emptyRest][emptyOne][emptyOne] if b.tophash[i] == emptyRest { break bucketloop } continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey() { k = *((*unsafe.Pointer)(k)) } if t.key.equal(key, k) { e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) if t.indirectelem() { e = *((*unsafe.Pointer)(e)) } return e } } } return unsafe.Pointer(&zeroVal[0]) }
// 如果触发了最大的 load factor,或者已经有太多 overflow buckets // 并且这个时刻没有在进行 growing 的途中,那么就开始 growing if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) { hashGrow(t, h) goto again // Growing the table invalidates everything, so try again }
// 前面在桶里找的时候,没有找到能塞这个 tophash 的位置 // 说明当前所有 buckets 都是满的,分配一个新的 bucket if inserti == nil { // The current bucket and all the overflow buckets connected to it are full, allocate a new one. newb := h.newoverflow(t, b) inserti = &newb.tophash[0] insertk = add(unsafe.Pointer(newb), dataOffset) elem = add(insertk, bucketCnt*uintptr(t.keysize)) }
// 把新的 key 和 value 存储到应插入的位置 if t.indirectkey() { kmem := newobject(t.key) *(*unsafe.Pointer)(insertk) = kmem insertk = kmem } if t.indirectelem() { vmem := newobject(t.elem) *(*unsafe.Pointer)(elem) = vmem } typedmemmove(t.key, insertk, key) *inserti = top h.count++
funcevacuate(t *maptype, h *hmap, oldbucket uintptr) { b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))) newbit := h.noldbuckets() if !evacuated(b) { // TODO: reuse overflow buckets instead of using new ones, if there // is no iterator using the old buckets. (If !oldIterator.)
// xy contains the x and y (low and high) evacuation destinations. var xy [2]evacDst x := &xy[0] x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize))) x.k = add(unsafe.Pointer(x.b), dataOffset) x.e = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() { // Only calculate y pointers if we're growing bigger. // Otherwise GC can see bad pointers. y := &xy[1] y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize))) y.k = add(unsafe.Pointer(y.b), dataOffset) y.e = add(y.k, bucketCnt*uintptr(t.keysize)) }
for ; b != nil; b = b.overflow(t) { k := add(unsafe.Pointer(b), dataOffset) e := add(k, bucketCnt*uintptr(t.keysize)) for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) { top := b.tophash[i] if isEmpty(top) { b.tophash[i] = evacuatedEmpty continue } if top < minTopHash { throw("bad map state") } k2 := k if t.indirectkey() { k2 = *((*unsafe.Pointer)(k2)) } var useY uint8 if !h.sameSizeGrow() { // Compute hash to make our evacuation decision (whether we need // to send this key/elem to bucket x or bucket y). hash := t.hasher(k2, uintptr(h.hash0)) if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) { // If key != key (NaNs), then the hash could be (and probably // will be) entirely different from the old hash. Moreover, // it isn't reproducible. Reproducibility is required in the // presence of iterators, as our evacuation decision must // match whatever decision the iterator made. // Fortunately, we have the freedom to send these keys either // way. Also, tophash is meaningless for these kinds of keys. // We let the low bit of tophash drive the evacuation decision. // We recompute a new random tophash for the next level so // these keys will get evenly distributed across all buckets // after multiple grows. useY = top & 1 top = tophash(hash) } else { if hash&newbit != 0 { useY = 1 } } }
if dst.i == bucketCnt { dst.b = h.newoverflow(t, dst.b) dst.i = 0 dst.k = add(unsafe.Pointer(dst.b), dataOffset) dst.e = add(dst.k, bucketCnt*uintptr(t.keysize)) } dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check if t.indirectkey() { *(*unsafe.Pointer)(dst.k) = k2 // copy pointer } else { typedmemmove(t.key, dst.k, k) // copy elem } if t.indirectelem() { *(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e) } else { typedmemmove(t.elem, dst.e, e) } dst.i++ // These updates might push these pointers past the end of the // key or elem arrays. That's ok, as we have the overflow pointer // at the end of the bucket to protect against pointing past the // end of the bucket. dst.k = add(dst.k, uintptr(t.keysize)) dst.e = add(dst.e, uintptr(t.elemsize)) } } // Unlink the overflow buckets & clear key/elem to help GC. if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 { b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)) // Preserve b.tophash because the evacuation // state is maintained there. ptr := add(b, dataOffset) n := uintptr(t.bucketsize) - dataOffset memclrHasPointers(ptr, n) } }
if oldbucket == h.nevacuate { advanceEvacuationMark(h, t, newbit) } }